Multi-output Gaussian processes in GPflow#
This notebook shows how to construct a multi-output GP model using GPflow, together with different interdomain inducing variables which lead to different approximation properties. GPflow provides a framework for specifying multioutput GP priors, and interdomain approximations which is - modular, by providing a consistent interface for the user of the resulting SVGP model, - extensible, by allowing new interdomain variables and kernels to be specified while reusing exising code where
possible, - efficient, by allowing the most efficient custom code path to be specified where desired.
Getting to grips with the maths and code can be a bit daunting, so to accompany the documentation there is an in-depth review on arXiv, which provides a unified mathematical framework, together with a high-level description of software design choices in GPflow.
This notebook shows the various design choices that can be made, to show the reader the flexibility of the framework. This is done in the hope that an example is provided that can be easily adapted to the special case that the reader wants to implement.
A reader who just wants to use a multioutput kernel should simply choose the most efficient set of inducing variables.
To cite this framework, please reference our arXiv paper.
@article{GPflow2020multioutput,
author = {{van der Wilk}, Mark and Dutordoir, Vincent and John, ST and
Artemev, Artem and Adam, Vincent and Hensman, James},
title = {A Framework for Interdomain and Multioutput {G}aussian Processes},
year = {2020},
journal = {arXiv:2003.01115},
url = {https://arxiv.org/abs/2003.01115}
}
\begin{equation} \newcommand{\GP}{\mathcal{GP}} \newcommand{\NN}{\mathcal{N}} \newcommand{\LL}{\mathcal{L}} \newcommand{\RR}{\mathbb{R}} \newcommand{\EE}{\mathbb{E}} \newcommand{\valpha}{\boldsymbol\alpha} \newcommand{\vf}{\mathbf{f}} \newcommand{\vF}{\mathbf{F}} \newcommand{\vg}{\mathbf{g}} \newcommand{\vW}{\mathbf{W}} \newcommand{\vI}{\mathbf{I}} \newcommand{\vZ}{\mathbf{Z}} \newcommand{\vu}{\mathbf{u}} \newcommand{\vU}{\mathbf{U}} \newcommand{\vX}{\mathbf{X}} \newcommand{\vY}{\mathbf{Y}} \newcommand{\identity}{\mathbb{I}} \end{equation}
Task#
We will consider a regression problem for functions \(f: \mathbb{R}^D \rightarrow \mathbb{R}^P\). We assume that the dataset is of the form \((X, f_1), \dots, (X, f_P)\), that is, we observe all the outputs for a particular input location (for cases where there are not fully observed outputs for each input, see A simple demonstration of coregionalization).
Here we assume a model of the form: \begin{equation} f(x) = W g(x), \end{equation} where \(g(x) \in \mathbb{R}^L\), \(f(x) \in \mathbb{R}^P\) and \(W \in \mathbb{R}^{P \times L}\). We assume that the outputs of \(g\) are uncorrelated, and that by mixing them with \(W\) they become correlated. In this notebook, we show how to build this model using Sparse Variational Gaussian Process (SVGP) for \(g\), which scales well with the numbers of data points and outputs.
Here we have two options for \(g\): 1. The output dimensions of \(g\) share the same kernel. 2. Each output of \(g\) has a separate kernel.
In addition, we have two further suboptions for the inducing inputs of \(g\): 1. The instances of \(g\) share the same inducing inputs. 2. Each output of \(g\) has its own set of inducing inputs.
The notation is as follows: - \(X \in \mathbb{R}^{N \times D}\) denotes the input - \(Y \in \RR^{N \times P}\) denotes the output - \(k_{1..L}\), \(L\) are kernels on \(\RR^{N \times D}\) - \(g_{1..L}\), \(L\) are independent \(\GP\)s with \(g_l \sim \GP(0,k_l)\) - \(f_{1..P}\), \(P\) are correlated \(\GP\)s with \(\vf = \vW \vg\)
[1]:
import matplotlib.pyplot as plt
import numpy as np
import gpflow as gpf
from gpflow.ci_utils import reduce_in_tests
from gpflow.utilities import print_summary
gpf.config.set_default_float(np.float64)
gpf.config.set_default_summary_fmt("notebook")
np.random.seed(0)
%matplotlib inline
MAXITER = reduce_in_tests(2000)
2023-05-03 23:15:04.331498: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-05-03 23:15:04.462766: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory
2023-05-03 23:15:04.462784: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
2023-05-03 23:15:04.503390: E tensorflow/stream_executor/cuda/cuda_blas.cc:2981] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
2023-05-03 23:15:05.290499: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory
2023-05-03 23:15:05.290590: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory
2023-05-03 23:15:05.290601: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
Generate synthetic data#
We create a utility function to generate synthetic data. We assume that:
[2]:
N = 100 # number of points
D = 1 # number of input dimensions
M = 15 # number of inducing points
L = 2 # number of latent GPs
P = 3 # number of observations = output dimensions
[3]:
def generate_data(N=100):
X = np.random.rand(N)[:, None] * 10 - 5 # Inputs = N x D
G = np.hstack((0.5 * np.sin(3 * X) + X, 3.0 * np.cos(X) - X)) # G = N x L
W = np.array([[0.5, -0.3, 1.5], [-0.4, 0.43, 0.0]]) # L x P
F = np.matmul(G, W) # N x P
Y = F + np.random.randn(*F.shape) * [0.2, 0.2, 0.2]
return X, Y
[4]:
X, Y = data = generate_data(N)
Zinit = np.linspace(-5, 5, M)[:, None]
We create a utility function for plotting:
[5]:
def plot_model(m, lower=-8.0, upper=8.0):
pX = np.linspace(lower, upper, 100)[:, None]
pY, pYv = m.predict_y(pX)
if pY.ndim == 3:
pY = pY[:, 0, :]
plt.plot(X, Y, "x")
plt.gca().set_prop_cycle(None)
plt.plot(pX, pY)
for i in range(pY.shape[1]):
top = pY[:, i] + 2.0 * pYv[:, i] ** 0.5
bot = pY[:, i] - 2.0 * pYv[:, i] ** 0.5
plt.fill_between(pX[:, 0], top, bot, alpha=0.3)
plt.xlabel("X")
plt.ylabel("f")
plt.title(f"ELBO: {m.elbo(data):.3}")
plt.plot(Z, Z * 0.0, "o")
Model the outputs of \(f(x)\) directly#
The three following examples show how to model the outputs of the model \(f(x)\) directly. Mathematically, this case is equivalent to having: \begin{equation} f(x) = I g(x), \end{equation} i.e. \(W = I\) and \(P = L\).
1. Shared independent multi-output kernel (MOK) and shared independent inducing variables#
Here the priors on all outputs are constrained to have the same kernel hyperparameters. We also share the inducing inputs between all outputs. The different GPs are independent both in the prior and the approximate posterior.
[6]:
# create multi-output kernel
kernel = gpf.kernels.SharedIndependent(
gpf.kernels.SquaredExponential() + gpf.kernels.Linear(), output_dim=P
)
# initialization of inducing input locations (M random points from the training inputs)
Z = Zinit.copy()
# create multi-output inducing variables from Z
iv = gpf.inducing_variables.SharedIndependentInducingVariables(
gpf.inducing_variables.InducingPoints(Z)
)
2023-05-03 23:15:08.466066: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcuda.so.1'; dlerror: libcuda.so.1: cannot open shared object file: No such file or directory
2023-05-03 23:15:08.466087: W tensorflow/stream_executor/cuda/cuda_driver.cc:263] failed call to cuInit: UNKNOWN ERROR (303)
2023-05-03 23:15:08.466106: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:156] kernel driver does not appear to be running on this host (d64c43fc0b71): /proc/driver/nvidia/version does not exist
2023-05-03 23:15:08.466371: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
[7]:
# create SVGP model as usual and optimize
m = gpf.models.SVGP(
kernel, gpf.likelihoods.Gaussian(), inducing_variable=iv, num_latent_gps=P
)
print_summary(m)
| name | class | transform | prior | trainable | shape | dtype | value |
|---|---|---|---|---|---|---|---|
| SVGP.kernel.kernel.kernels[0].variance | Parameter | Softplus | True | () | float64 | 1.0 | |
| SVGP.kernel.kernel.kernels[0].lengthscales | Parameter | Softplus | True | () | float64 | 1.0 | |
| SVGP.kernel.kernel.kernels[1].variance | Parameter | Softplus | True | () | float64 | 1.0 | |
| SVGP.likelihood.variance | Parameter | Softplus + Shift | True | () | float64 | 1.0 | |
| SVGP.inducing_variable.inducing_variable.Z | Parameter | Identity | True | (15, 1) | float64 | [[-5.... | |
| SVGP.q_mu | Parameter | Identity | True | (15, 3) | float64 | [[0., 0., 0.... | |
| SVGP.q_sqrt | Parameter | FillTriangular | True | (3, 15, 15) | float64 | [[[1., 0., 0.... |
[8]:
def optimize_model_with_scipy(model):
optimizer = gpf.optimizers.Scipy()
optimizer.minimize(
model.training_loss_closure(data),
variables=model.trainable_variables,
method="l-bfgs-b",
options={"disp": 50, "maxiter": MAXITER},
)
optimize_model_with_scipy(m)
RUNNING THE L-BFGS-B CODE
* * *
Machine precision = 2.220D-16
N = 424 M = 10
At X0 0 variables are exactly at the bounds
At iterate 0 f= 3.26251D+03 |proj g|= 1.79322D+03
At iterate 50 f= 1.60046D+02 |proj g|= 2.23880D+01
At iterate 100 f= 6.24335D+01 |proj g|= 2.64482D+01
This problem is unconstrained.
At iterate 150 f= 5.47594D+01 |proj g|= 2.30324D+01
At iterate 200 f= 5.09409D+01 |proj g|= 1.79887D+01
At iterate 250 f= 4.85812D+01 |proj g|= 1.69594D+01
At iterate 300 f= 4.68431D+01 |proj g|= 1.00237D+01
At iterate 350 f= 4.56696D+01 |proj g|= 6.56927D+00
At iterate 400 f= 4.46591D+01 |proj g|= 7.61969D+00
At iterate 450 f= 4.37202D+01 |proj g|= 9.01165D+00
At iterate 500 f= 4.30875D+01 |proj g|= 8.36795D+00
At iterate 550 f= 4.27808D+01 |proj g|= 1.06301D+01
At iterate 600 f= 4.26544D+01 |proj g|= 2.51395D+00
At iterate 650 f= 4.25500D+01 |proj g|= 2.33529D+00
At iterate 700 f= 4.24944D+01 |proj g|= 2.56079D+00
At iterate 750 f= 4.24630D+01 |proj g|= 8.78334D-01
At iterate 800 f= 4.24463D+01 |proj g|= 4.26999D-01
At iterate 850 f= 4.24381D+01 |proj g|= 4.16215D-01
At iterate 900 f= 4.24335D+01 |proj g|= 4.11149D-01
At iterate 950 f= 4.24295D+01 |proj g|= 8.49405D-01
At iterate 1000 f= 4.24265D+01 |proj g|= 1.33535D+00
At iterate 1050 f= 4.24249D+01 |proj g|= 1.05105D-01
At iterate 1100 f= 4.24240D+01 |proj g|= 3.28053D-01
At iterate 1150 f= 4.24235D+01 |proj g|= 1.67576D-01
At iterate 1200 f= 4.24230D+01 |proj g|= 1.49874D-01
At iterate 1250 f= 4.24225D+01 |proj g|= 5.82735D-02
At iterate 1300 f= 4.24221D+01 |proj g|= 1.34652D-01
At iterate 1350 f= 4.24218D+01 |proj g|= 2.27220D-01
At iterate 1400 f= 4.24214D+01 |proj g|= 1.21356D-01
At iterate 1450 f= 4.24211D+01 |proj g|= 2.22174D-01
At iterate 1500 f= 4.24208D+01 |proj g|= 2.25751D-01
At iterate 1550 f= 4.24205D+01 |proj g|= 1.64768D-01
At iterate 1600 f= 4.24205D+01 |proj g|= 3.55818D-02
At iterate 1650 f= 4.24204D+01 |proj g|= 2.40386D-02
At iterate 1700 f= 4.24204D+01 |proj g|= 1.07473D-01
* * *
Tit = total number of iterations
Tnf = total number of function evaluations
Tnint = total number of segments explored during Cauchy searches
Skip = number of BFGS updates skipped
Nact = number of active bounds at final generalized Cauchy point
Projg = norm of the final projected gradient
F = final function value
* * *
N Tit Tnf Tnint Skip Nact Projg F
424 1700 1813 1 0 0 1.075D-01 4.242D+01
F = 42.420424440816490
CONVERGENCE: REL_REDUCTION_OF_F_<=_FACTR*EPSMCH
[9]:
print_summary(m)
| name | class | transform | prior | trainable | shape | dtype | value |
|---|---|---|---|---|---|---|---|
| SVGP.kernel.kernel.kernels[0].variance | Parameter | Softplus | True | () | float64 | 0.92725 | |
| SVGP.kernel.kernel.kernels[0].lengthscales | Parameter | Softplus | True | () | float64 | 0.79819 | |
| SVGP.kernel.kernel.kernels[1].variance | Parameter | Softplus | True | () | float64 | 1.2139 | |
| SVGP.likelihood.variance | Parameter | Softplus + Shift | True | () | float64 | 0.03966 | |
| SVGP.inducing_variable.inducing_variable.Z | Parameter | Identity | True | (15, 1) | float64 | [[-4.83959... | |
| SVGP.q_mu | Parameter | Identity | True | (15, 3) | float64 | [[-0.90097, 0.69851, -1.4739... | |
| SVGP.q_sqrt | Parameter | FillTriangular | True | (3, 15, 15) | float64 | [[[1.7120e-02, 0.0000e+00, 0.0000e+00... |
[10]:
# Plot predictions and observations
plot_model(m)
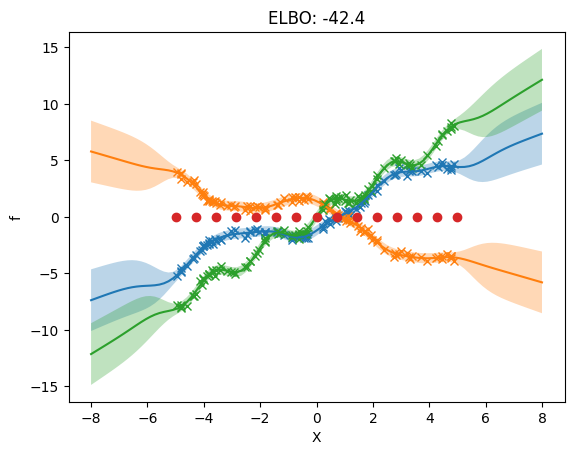
[11]:
print_summary(m.kernel)
m.kernel.kernel.kernels[0].lengthscales
| name | class | transform | prior | trainable | shape | dtype | value |
|---|---|---|---|---|---|---|---|
| SharedIndependent.kernel.kernels[0].variance | Parameter | Softplus | True | () | float64 | 0.92725 | |
| SharedIndependent.kernel.kernels[0].lengthscales | Parameter | Softplus | True | () | float64 | 0.79819 | |
| SharedIndependent.kernel.kernels[1].variance | Parameter | Softplus | True | () | float64 | 1.2139 |
[11]:
<Parameter: name=softplus, dtype=float64, shape=[], fn="softplus", numpy=0.7981918482945918>
2. Separate independent MOK and shared independent inducing variables#
Here we allow different hyperparameters for the priors of each output. We still share the inducing inputs between all outputs.
[12]:
# Create list of kernels for each output
kern_list = [
gpf.kernels.SquaredExponential() + gpf.kernels.Linear() for _ in range(P)
]
# Create multi-output kernel from kernel list
kernel = gpf.kernels.SeparateIndependent(kern_list)
# initialization of inducing input locations (M random points from the training inputs)
Z = Zinit.copy()
# create multi-output inducing variables from Z
iv = gpf.inducing_variables.SharedIndependentInducingVariables(
gpf.inducing_variables.InducingPoints(Z)
)
[13]:
# create SVGP model as usual and optimize
m = gpf.models.SVGP(
kernel, gpf.likelihoods.Gaussian(), inducing_variable=iv, num_latent_gps=P
)
[14]:
optimize_model_with_scipy(m)
WARNING:tensorflow:From /tmp/max_venv/lib/python3.10/site-packages/tensorflow/python/util/deprecation.py:629: calling map_fn_v2 (from tensorflow.python.ops.map_fn) with dtype is deprecated and will be removed in a future version.
Instructions for updating:
Use fn_output_signature instead
RUNNING THE L-BFGS-B CODE
* * *
Machine precision = 2.220D-16
N = 430 M = 10
At X0 0 variables are exactly at the bounds
At iterate 0 f= 3.26251D+03 |proj g|= 1.79322D+03
This problem is unconstrained.
At iterate 50 f= 1.94337D+02 |proj g|= 7.19142D+00
At iterate 100 f= 1.66814D+02 |proj g|= 3.26283D+01
At iterate 150 f= 6.00999D+01 |proj g|= 2.15028D+01
At iterate 200 f= 4.97328D+01 |proj g|= 1.95679D+01
At iterate 250 f= 4.64796D+01 |proj g|= 8.71966D+00
At iterate 300 f= 4.44078D+01 |proj g|= 5.29028D+00
At iterate 350 f= 4.30525D+01 |proj g|= 9.00944D+00
At iterate 400 f= 4.15516D+01 |proj g|= 1.03807D+01
At iterate 450 f= 4.04783D+01 |proj g|= 9.62300D+00
At iterate 500 f= 3.97566D+01 |proj g|= 6.23925D+00
At iterate 550 f= 3.89135D+01 |proj g|= 2.19500D+01
At iterate 600 f= 3.82752D+01 |proj g|= 9.02205D+00
At iterate 650 f= 3.79721D+01 |proj g|= 3.18852D+00
At iterate 700 f= 3.77513D+01 |proj g|= 2.32701D+00
At iterate 750 f= 3.75961D+01 |proj g|= 8.92977D+00
At iterate 800 f= 3.74777D+01 |proj g|= 2.63936D+00
At iterate 850 f= 3.73929D+01 |proj g|= 2.87805D+00
At iterate 900 f= 3.73332D+01 |proj g|= 1.00035D+00
At iterate 950 f= 3.72974D+01 |proj g|= 1.60231D+00
At iterate 1000 f= 3.72751D+01 |proj g|= 1.69327D+00
At iterate 1050 f= 3.72575D+01 |proj g|= 5.20291D-01
At iterate 1100 f= 3.72450D+01 |proj g|= 1.99396D+00
At iterate 1150 f= 3.72328D+01 |proj g|= 1.45785D+00
At iterate 1200 f= 3.72250D+01 |proj g|= 5.66249D-01
At iterate 1250 f= 3.72197D+01 |proj g|= 2.88656D+00
At iterate 1300 f= 3.72131D+01 |proj g|= 3.59536D-01
At iterate 1350 f= 3.72047D+01 |proj g|= 8.53286D-01
At iterate 1400 f= 3.71976D+01 |proj g|= 1.43617D+00
At iterate 1450 f= 3.71928D+01 |proj g|= 2.20744D-01
At iterate 1500 f= 3.71874D+01 |proj g|= 1.19581D+00
At iterate 1550 f= 3.71839D+01 |proj g|= 4.57358D-01
At iterate 1600 f= 3.71815D+01 |proj g|= 2.80283D-01
At iterate 1650 f= 3.71800D+01 |proj g|= 1.86547D-01
At iterate 1700 f= 3.71792D+01 |proj g|= 1.92775D-01
At iterate 1750 f= 3.71787D+01 |proj g|= 1.79399D-01
At iterate 1800 f= 3.71785D+01 |proj g|= 2.37693D-01
At iterate 1850 f= 3.71783D+01 |proj g|= 1.12377D-01
At iterate 1900 f= 3.71782D+01 |proj g|= 1.58807D-01
At iterate 1950 f= 3.71781D+01 |proj g|= 9.27521D-02
At iterate 2000 f= 3.71780D+01 |proj g|= 1.01838D-01
* * *
Tit = total number of iterations
Tnf = total number of function evaluations
Tnint = total number of segments explored during Cauchy searches
Skip = number of BFGS updates skipped
Nact = number of active bounds at final generalized Cauchy point
Projg = norm of the final projected gradient
F = final function value
* * *
N Tit Tnf Tnint Skip Nact Projg F
430 2000 2140 1 0 0 1.018D-01 3.718D+01
F = 37.178028020708659
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT
[15]:
print_summary(m.kernel)
| name | class | transform | prior | trainable | shape | dtype | value |
|---|---|---|---|---|---|---|---|
| SeparateIndependent.kernels[0].kernels[0].variance | Parameter | Softplus | True | () | float64 | 0.86408 | |
| SeparateIndependent.kernels[0].kernels[0].lengthscales | Parameter | Softplus | True | () | float64 | 0.93467 | |
| SeparateIndependent.kernels[0].kernels[1].variance | Parameter | Softplus | True | () | float64 | 0.86262 | |
| SeparateIndependent.kernels[1].kernels[0].variance | Parameter | Softplus | True | () | float64 | 0.75081 | |
| SeparateIndependent.kernels[1].kernels[0].lengthscales | Parameter | Softplus | True | () | float64 | 0.96981 | |
| SeparateIndependent.kernels[1].kernels[1].variance | Parameter | Softplus | True | () | float64 | 0.53054 | |
| SeparateIndependent.kernels[2].kernels[0].variance | Parameter | Softplus | True | () | float64 | 1.11149 | |
| SeparateIndependent.kernels[2].kernels[0].lengthscales | Parameter | Softplus | True | () | float64 | 0.74912 | |
| SeparateIndependent.kernels[2].kernels[1].variance | Parameter | Softplus | True | () | float64 | 2.21307 |
[16]:
plot_model(m)
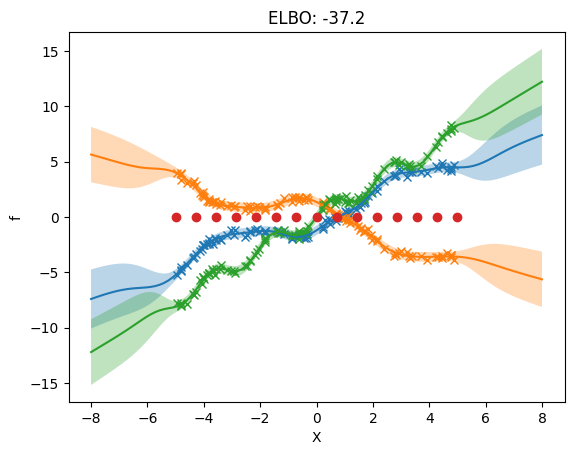
[17]:
[k.kernels[0].lengthscales for k in m.kernel.kernels]
[17]:
[<Parameter: name=softplus, dtype=float64, shape=[], fn="softplus", numpy=0.9346736406655387>,
<Parameter: name=softplus, dtype=float64, shape=[], fn="softplus", numpy=0.9698064672110547>,
<Parameter: name=softplus, dtype=float64, shape=[], fn="softplus", numpy=0.7491181736855458>]
3. Separate independent kernel and separate independent inducing variables#
Here we allow different hyperparameters for the priors of each output. We now allow different inducing inputs for each output.
[18]:
# Create list of kernels for each output
kern_list = [
gpf.kernels.SquaredExponential() + gpf.kernels.Linear() for _ in range(P)
]
# Create multi-output kernel from kernel list
kernel = gpf.kernels.SeparateIndependent(kern_list)
# initialization of inducing input locations, one set of locations per output
Zs = [Zinit.copy() for _ in range(P)]
# initialize as list inducing inducing variables
iv_list = [gpf.inducing_variables.InducingPoints(Z) for Z in Zs]
# create multi-output inducing variables from iv_list
iv = gpf.inducing_variables.SeparateIndependentInducingVariables(iv_list)
NOTE: While the inducing points are independent, there needs to be the same number of inducing points per dimension.
[19]:
# create SVGP model as usual and optimize
m = gpf.models.SVGP(
kernel, gpf.likelihoods.Gaussian(), inducing_variable=iv, num_latent_gps=P
)
[20]:
optimize_model_with_scipy(m)
RUNNING THE L-BFGS-B CODE
* * *
Machine precision = 2.220D-16
N = 460 M = 10
At X0 0 variables are exactly at the bounds
At iterate 0 f= 3.26251D+03 |proj g|= 1.79322D+03
This problem is unconstrained.
At iterate 50 f= 1.91729D+02 |proj g|= 6.27078D+00
At iterate 100 f= 1.05481D+02 |proj g|= 4.93334D+01
At iterate 150 f= 5.20108D+01 |proj g|= 2.94272D+01
At iterate 200 f= 4.67145D+01 |proj g|= 2.18349D+01
At iterate 250 f= 4.42325D+01 |proj g|= 2.92998D+01
At iterate 300 f= 4.28052D+01 |proj g|= 6.52055D+00
At iterate 350 f= 4.12258D+01 |proj g|= 7.51169D+00
At iterate 400 f= 3.96203D+01 |proj g|= 9.03021D+00
At iterate 450 f= 3.86267D+01 |proj g|= 6.21595D+00
At iterate 500 f= 3.81482D+01 |proj g|= 4.72608D+00
At iterate 550 f= 3.79072D+01 |proj g|= 3.26377D+00
At iterate 600 f= 3.77769D+01 |proj g|= 3.26844D+00
At iterate 650 f= 3.76880D+01 |proj g|= 2.81014D+00
At iterate 700 f= 3.75912D+01 |proj g|= 2.54230D+00
At iterate 750 f= 3.74843D+01 |proj g|= 1.60409D+00
At iterate 800 f= 3.73878D+01 |proj g|= 3.66023D+00
At iterate 850 f= 3.72751D+01 |proj g|= 1.80375D+00
At iterate 900 f= 3.72000D+01 |proj g|= 5.29436D+00
At iterate 950 f= 3.71556D+01 |proj g|= 1.57365D+00
At iterate 1000 f= 3.71109D+01 |proj g|= 1.92874D+00
At iterate 1050 f= 3.70677D+01 |proj g|= 4.03134D+00
At iterate 1100 f= 3.70264D+01 |proj g|= 1.65964D+00
At iterate 1150 f= 3.70021D+01 |proj g|= 1.94705D+00
At iterate 1200 f= 3.69893D+01 |proj g|= 7.90922D-01
At iterate 1250 f= 3.69794D+01 |proj g|= 6.15579D-01
At iterate 1300 f= 3.69724D+01 |proj g|= 8.61087D-01
At iterate 1350 f= 3.69680D+01 |proj g|= 8.38448D-01
At iterate 1400 f= 3.69652D+01 |proj g|= 5.08162D-01
At iterate 1450 f= 3.69621D+01 |proj g|= 4.89696D-01
At iterate 1500 f= 3.69592D+01 |proj g|= 7.00189D-01
At iterate 1550 f= 3.69560D+01 |proj g|= 5.52089D-01
At iterate 1600 f= 3.69537D+01 |proj g|= 1.50911D-01
At iterate 1650 f= 3.69521D+01 |proj g|= 8.23773D-01
At iterate 1700 f= 3.69512D+01 |proj g|= 1.88230D-01
At iterate 1750 f= 3.69506D+01 |proj g|= 2.76983D-01
At iterate 1800 f= 3.69502D+01 |proj g|= 7.08849D-01
At iterate 1850 f= 3.69499D+01 |proj g|= 5.98787D-01
At iterate 1900 f= 3.69495D+01 |proj g|= 2.53047D-01
At iterate 1950 f= 3.69491D+01 |proj g|= 2.12177D-01
At iterate 2000 f= 3.69488D+01 |proj g|= 1.45673D-01
* * *
Tit = total number of iterations
Tnf = total number of function evaluations
Tnint = total number of segments explored during Cauchy searches
Skip = number of BFGS updates skipped
Nact = number of active bounds at final generalized Cauchy point
Projg = norm of the final projected gradient
F = final function value
* * *
N Tit Tnf Tnint Skip Nact Projg F
460 2000 2141 1 0 0 1.457D-01 3.695D+01
F = 36.948765982874498
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT
[21]:
plot_model(m)
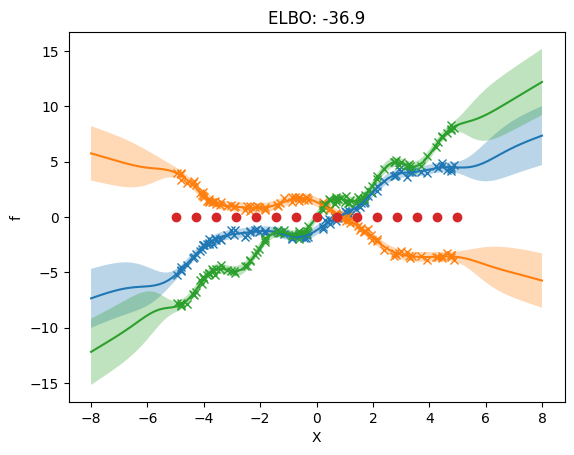
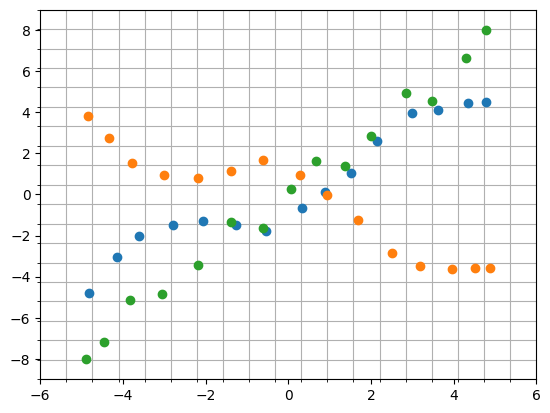
The following plot shows that we use different inducing inputs in each output dimension.
[22]:
for i in range(len(m.inducing_variable.inducing_variable_list)):
q_mu_unwhitened, q_var_unwhitened = m.predict_f(
m.inducing_variable.inducing_variable_list[i].Z
)
plt.plot(
m.inducing_variable.inducing_variable_list[i].Z.numpy(),
q_mu_unwhitened[:, i, None].numpy(),
"o",
)
plt.gca().set_xticks(np.linspace(-6, 6, 20), minor=True)
plt.gca().set_yticks(np.linspace(-9, 9, 20), minor=True)
plt.grid(which="minor")
[23]:
m.inducing_variable.inducing_variable_list
[23]:
ListWrapper([<gpflow.inducing_variables.inducing_variables.InducingPoints object at 0x7f44683f6050>, <gpflow.inducing_variables.inducing_variables.InducingPoints object at 0x7f44683f7ac0>, <gpflow.inducing_variables.inducing_variables.InducingPoints object at 0x7f44683f6e90>])
Model \(f(x)\) by doing inference in the \(g\) space#
Mixed kernel and uncorrelated inducing variables#
Remember the general case: \(f(x) = W g(x)\), where \(g(x) \in \mathbb{R}^L\), \(f(x) \in \mathbb{R}^P\) and \(W \in \mathbb{R}^{P \times L}\), where \(L \leq P\). We assume that the outputs of \(g\) are uncorrelated, and by mixing them with \(W\) they become correlated. With this setup we perform the optimal routine to calculate the conditional. Namely, calculate the conditional of the uncorrelated latent \(g\) and afterwards project the mean and variance using the mixing matrix: \(\mu_f = W \mu_g\) and \(\Sigma_f = W\Sigma_g W^\top\)
\(K_{uu} = L \times M \times M\)
\(K_{uf} = L \times M \times N\)
[24]:
# Create list of kernels for each output
kern_list = [
gpf.kernels.SquaredExponential() + gpf.kernels.Linear() for _ in range(L)
]
# Create multi-output kernel from kernel list
kernel = gpf.kernels.LinearCoregionalization(
kern_list, W=np.random.randn(P, L)
) # Notice that we initialise the mixing matrix W
# initialisation of inducing input locations (M random points from the training inputs)
Z = Zinit.copy()
# create multi-output inducing variables from Z
iv = gpf.inducing_variables.SharedIndependentInducingVariables(
gpf.inducing_variables.InducingPoints(Z)
)
[25]:
# initialize mean of variational posterior to be of shape MxL
q_mu = np.zeros((M, L))
# initialize \sqrt(Σ) of variational posterior to be of shape LxMxM
q_sqrt = np.repeat(np.eye(M)[None, ...], L, axis=0) * 1.0
# create SVGP model as usual and optimize
m = gpf.models.SVGP(
kernel,
gpf.likelihoods.Gaussian(),
inducing_variable=iv,
q_mu=q_mu,
q_sqrt=q_sqrt,
)
[26]:
optimize_model_with_scipy(m)
This problem is unconstrained.
RUNNING THE L-BFGS-B CODE
* * *
Machine precision = 2.220D-16
N = 298 M = 10
At X0 0 variables are exactly at the bounds
At iterate 0 f= 7.44521D+03 |proj g|= 6.62929D+03
At iterate 50 f= 3.17536D+02 |proj g|= 4.85678D+00
At iterate 100 f= 1.84264D+02 |proj g|= 1.74463D+02
At iterate 150 f= 1.18739D+02 |proj g|= 1.20540D+02
At iterate 200 f= 4.03397D+01 |proj g|= 7.37977D+01
At iterate 250 f= 2.35736D+01 |proj g|= 3.19784D+01
At iterate 300 f= 1.85507D+01 |proj g|= 1.90258D+01
At iterate 350 f= 1.38568D+01 |proj g|= 2.18620D+01
At iterate 400 f= 1.06028D+01 |proj g|= 3.83948D+01
At iterate 450 f= 8.44384D+00 |proj g|= 1.64975D+01
At iterate 500 f= 6.90463D+00 |proj g|= 7.77259D+00
At iterate 550 f= 5.55241D+00 |proj g|= 1.50941D+01
At iterate 600 f= 4.41403D+00 |proj g|= 1.54117D+01
At iterate 650 f= 3.67700D+00 |proj g|= 1.88611D+01
At iterate 700 f= 3.19464D+00 |proj g|= 3.68109D+00
At iterate 750 f= 2.86225D+00 |proj g|= 1.10662D+01
At iterate 800 f= 2.55773D+00 |proj g|= 3.86343D+00
At iterate 850 f= 2.02080D+00 |proj g|= 6.48201D+00
At iterate 900 f= 1.64970D+00 |proj g|= 2.93980D+00
At iterate 950 f= 1.47558D+00 |proj g|= 8.81754D+00
At iterate 1000 f= 1.34171D+00 |proj g|= 1.41515D+00
At iterate 1050 f= 1.26776D+00 |proj g|= 1.10931D+00
At iterate 1100 f= 1.21259D+00 |proj g|= 2.60048D+00
At iterate 1150 f= 1.13337D+00 |proj g|= 8.38712D-01
At iterate 1200 f= 1.02389D+00 |proj g|= 1.74448D+00
At iterate 1250 f= 9.45899D-01 |proj g|= 5.74669D+00
At iterate 1300 f= 8.89688D-01 |proj g|= 2.71870D+00
At iterate 1350 f= 8.30694D-01 |proj g|= 2.65540D+00
At iterate 1400 f= 7.87407D-01 |proj g|= 2.00173D+00
At iterate 1450 f= 7.49752D-01 |proj g|= 1.18554D+00
At iterate 1500 f= 7.27385D-01 |proj g|= 1.23276D+00
At iterate 1550 f= 7.09314D-01 |proj g|= 1.69974D+00
At iterate 1600 f= 6.97240D-01 |proj g|= 5.40155D-01
At iterate 1650 f= 6.87100D-01 |proj g|= 1.30062D+00
At iterate 1700 f= 6.77038D-01 |proj g|= 7.07311D-01
At iterate 1750 f= 6.67227D-01 |proj g|= 1.13528D+00
At iterate 1800 f= 6.59190D-01 |proj g|= 9.66881D-01
At iterate 1850 f= 6.50920D-01 |proj g|= 3.86379D+00
At iterate 1900 f= 6.43698D-01 |proj g|= 3.26855D-01
At iterate 1950 f= 6.37257D-01 |proj g|= 2.48417D-01
At iterate 2000 f= 6.32587D-01 |proj g|= 7.10780D-01
* * *
Tit = total number of iterations
Tnf = total number of function evaluations
Tnint = total number of segments explored during Cauchy searches
Skip = number of BFGS updates skipped
Nact = number of active bounds at final generalized Cauchy point
Projg = norm of the final projected gradient
F = final function value
* * *
N Tit Tnf Tnint Skip Nact Projg F
298 2000 2193 1 0 0 7.108D-01 6.326D-01
F = 0.63258728580373713
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT
[27]:
plot_model(m)
Illustration of GPflow’s multi-output capabilities#
This section shows the inheritance structure in GPflow’s multi-output framework.
Multi-output kernels (MOK) class diagram#
We include three multi-output kernels: - SharedIndependent: This kernel is included mainly as an illustration of specifying a conditional using the multiple dispatch framework. The same functionality is provided by using a normal kernel and passing in multiple approximate posteriors by stacking q_mu and q_sqrt. - SeparateIndependent: This kernel allows you to use different priors for each output GP. - LinearCoregionalization: This kernel describes the prior of the linear
model of coregionalization. As shown previously, this implementation supports various inducing point approximations. 
We include several base classes. Two are noteworthy: - MultioutputKernel is included to be the base class for all multi-output kernels. - IndepedentLatent is the base class for all multi-output kernels which are constructed from independent latent processes. Including this kernel allows the specification of a default approximation method which, while not the most efficient, does take advantage of some structure. It can be applied to any kernel constructed from independent latent
processes.
There is a similarity in the meaning of SeparateIndependent and IndependentLatent. Both kernels indicate that independent processes are used, and that \(\mathbf{K}_{\bf uu}\) can therefore be represented as a [L, M, M] tensor. It could therefore be suggested that SeparateIndependent be the parent class of all “independent latent” kernels, instead of having a separate IndependentLatent class. We decided against this because: - this would increase the complexity in
specifying conditionals() for the otherwise simple multi-output kernels SeparateIndependent and SharedIndependent. - we did not want to specify too much of an implementation in IndependentLatent, leaving implementation details to child classes. Using SeparateIndependent as the base class would force all child classes to be a Combination kernel.
Multi-output inducing variables class diagram#

Inducing points#
The goal of this class is to provide inducing variables that can be used with any kernel, even if the method ends up being slow.
The multiouput framework extends InducingPoints to work with multi-output kernels. Just like for single-output kernels, we want InducingPoints to work for all MultioutputKernels. We do this by defining InducingPoints to take all outputs for specific inducing inputs as inducing variables.
Implemented combinations#
Multiple dispatch is applied to both Kuu(), Kuf(), and conditional(). The return values of the covariances can therefore be tailored to a specific implementation of conditional(). The following table lists combinations which are currently available in GPflow. Thanks to the multiple dispatch code, implementing your own outside of GPflow should require only a small amount of code!
Inducing variable class |
Kernel |
Kuu |
Kuf |
conditional |
note |
|---|---|---|---|---|---|
|
|
|
|
|
Works for all kernels, but might be
very inefficient. In this case
|
|
|
|
|
|
The combination of these two classes is in a sense redundant, because we can achieve the same behavior by using the single output Kernel and InducingVariable classes. They are added for illustrative purposes. Thanks to the conditional dispatch, the most efficient code path is used. |
|
|
|
|
|
We loop P times over the
|
|
|
|
|
|
We loop P times over the
|
|
|
|
|
|
We loop P times over the
|
|
|
|
|
|
Implementation which only requires
custom |
|
|
|
|
|
Implementation which only requires
custom |
|
|
|
|
|
This is the most efficient implementation for linear coregionalization. The inducing outputs live in g-space. Here we use the output of the base conditional and project the mean and covariance with the mixing matrix W. |
|
|
|
|
|
This is the most efficient implementation for linear coregionalization. The inducing outputs live in g-space. Here we use the output of the base conditional and project the mean and covariance with the mixing matrix W. |
Debugging: introspect#
Given all these possibilities it can be hard to determine which conditional will be called for which set of kernel and inducing variable. The following method lets you proactively introspect which implementation will be executed. This can be useful when debugging new code.
[28]:
def inspect_conditional(inducing_variable_type, kernel_type):
"""
Helper function returning the exact implementation called
by the multiple dispatch `conditional` given the type of
kernel and inducing variable.
:param inducing_variable_type:
Type of the inducing variable
:param kernel_type:
Type of the kernel
:return: String
Contains the name, the file and the linenumber of the
implementation.
"""
import inspect
from gpflow.conditionals import conditional
implementation = conditional.dispatch(
object, inducing_variable_type, kernel_type, object
)
info = dict(inspect.getmembers(implementation))
return info["__code__"]
# Example:
inspect_conditional(
gpf.inducing_variables.SharedIndependentInducingVariables,
gpf.kernels.SharedIndependent,
)
[28]:
<code object wrapped_function at 0x7f44742296e0, file "/tmp/max_venv/lib/python3.10/site-packages/check_shapes/decorator.py", line 118>
Further Reading:#
A simple demonstration of coregionalization, which details other GPflow features for multi-output prediction without fully observed outputs.