Basic (binary) GP classification model#
This notebook shows how to build a GP classification model using variational inference. Here we consider binary (two-class, 0 vs. 1) classification only (there is a separate notebook on multiclass classification). We first look at a one-dimensional example, and then show how you can adapt this when the input space is two-dimensional.
[1]:
import numpy as np
import gpflow
import tensorflow as tf
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams["figure.figsize"] = (8, 4)
2022-05-10 11:10:05.576366: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory
2022-05-10 11:10:05.576393: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
One-dimensional example#
First of all, let’s have a look at the data. X and Y denote the input and output values. NOTE: X and Y must be two-dimensional NumPy arrays, \(N \times 1\) or \(N \times D\), where \(D\) is the number of input dimensions/features, with the same number of rows as \(N\) (one for each data point):
[2]:
X = np.genfromtxt("data/classif_1D_X.csv").reshape(-1, 1)
Y = np.genfromtxt("data/classif_1D_Y.csv").reshape(-1, 1)
plt.figure(figsize=(10, 6))
_ = plt.plot(X, Y, "C3x", ms=8, mew=2)

Reminders on GP classification#
For a binary classification model using GPs, we can simply use a Bernoulli likelihood. The details of the generative model are as follows:
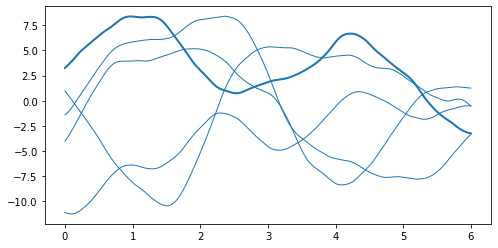
1. Define the latent GP: we start from a Gaussian process \(f \sim \mathcal{GP}(0, k(\cdot, \cdot'))\):
[3]:
# build the kernel and covariance matrix
k = gpflow.kernels.Matern52(variance=20.0)
x_grid = np.linspace(0, 6, 200).reshape(-1, 1)
K = k(x_grid)
# sample from a multivariate normal
rng = np.random.RandomState(6)
L = np.linalg.cholesky(K)
f_grid = np.dot(L, rng.randn(200, 5))
plt.plot(x_grid, f_grid, "C0", linewidth=1)
_ = plt.plot(x_grid, f_grid[:, 1], "C0", linewidth=2)
2022-05-10 11:10:08.398392: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcuda.so.1'; dlerror: libcuda.so.1: cannot open shared object file: No such file or directory
2022-05-10 11:10:08.398421: W tensorflow/stream_executor/cuda/cuda_driver.cc:269] failed call to cuInit: UNKNOWN ERROR (303)
2022-05-10 11:10:08.398441: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:156] kernel driver does not appear to be running on this host (49c966262641): /proc/driver/nvidia/version does not exist
2022-05-10 11:10:08.398733: I tensorflow/core/platform/cpu_feature_guard.cc:151] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
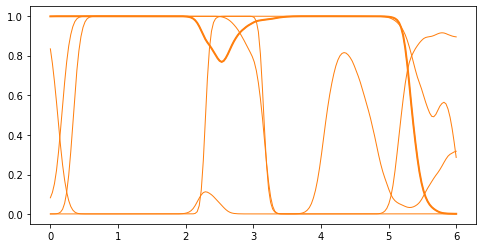
2. Squash them to :math:`[0, 1]`: the samples of the GP are mapped to \([0, 1]\). By default, GPflow uses the standard normal cumulative distribution function (inverse probit function): \(p(x) = \Phi(f(x)) = \frac{1}{2} (1 + \operatorname{erf}(x / \sqrt{2}))\). (This choice has the advantage that predictive mean, variance and density can be computed analytically, but any choice of invlink is possible, e.g. the logit \(p(x) = \frac{\exp(f(x))}{1 + \exp(f(x))}\). Simply pass
another function as the invlink argument to the Bernoulli likelihood class.)
[4]:
def invlink(f):
return gpflow.likelihoods.Bernoulli().invlink(f).numpy()
p_grid = invlink(f_grid)
plt.plot(x_grid, p_grid, "C1", linewidth=1)
_ = plt.plot(x_grid, p_grid[:, 1], "C1", linewidth=2)
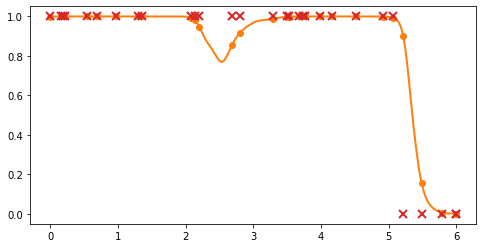
3. Sample from a Bernoulli: for each observation point \(X_i\), the class label \(Y_i \in \{0, 1\}\) is generated by sampling from a Bernoulli distribution \(Y_i \sim \mathcal{B}(g(X_i))\).
[5]:
# Select some input locations
ind = rng.randint(0, 200, (30,))
X_gen = x_grid[ind]
# evaluate probability and get Bernoulli draws
p = p_grid[ind, 1:2]
Y_gen = rng.binomial(1, p)
# plot
plt.plot(x_grid, p_grid[:, 1], "C1", linewidth=2)
plt.plot(X_gen, p, "C1o", ms=6)
_ = plt.plot(X_gen, Y_gen, "C3x", ms=8, mew=2)
Implementation with GPflow#
For the model described above, the posterior \(f(x)|Y\) (say \(p\)) is not Gaussian any more and does not have a closed-form expression. A common approach is then to look for the best approximation of this posterior by a tractable distribution (say \(q\)) such as a Gaussian distribution. In variational inference, the quality of an approximation is measured by the Kullback-Leibler divergence \(\mathrm{KL}[q \| p]\). For more details on this model, see Nickisch and Rasmussen (2008).
The inference problem is thus turned into an optimization problem: finding the best parameters for \(q\). In our case, we introduce \(U \sim \mathcal{N}(q_\mu, q_\Sigma)\), and we choose \(q\) to have the same distribution as \(f | f(X) = U\). The parameters \(q_\mu\) and \(q_\Sigma\) can be seen as parameters of \(q\), which can be optimized in order to minimise \(\mathrm{KL}[q \| p]\).
This variational inference model is called VGP in GPflow:
[6]:
m = gpflow.models.VGP(
(X, Y), likelihood=gpflow.likelihoods.Bernoulli(), kernel=gpflow.kernels.Matern52()
)
opt = gpflow.optimizers.Scipy()
opt.minimize(m.training_loss, variables=m.trainable_variables)
2022-05-10 11:10:09.457728: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
[6]:
fun: 11.67861091602181
hess_inv: <1327x1327 LbfgsInvHessProduct with dtype=float64>
jac: array([ 2.16825361e-04, -5.33011994e-05, 1.15138805e-04, ...,
4.93346126e-08, -2.28957102e-04, -2.36046930e-05])
message: 'CONVERGENCE: REL_REDUCTION_OF_F_<=_FACTR*EPSMCH'
nfev: 157
nit: 153
njev: 157
status: 0
success: True
x: array([-1.11966222, 0.26195969, -0.10535319, ..., 0.99989414,
1.4192545 , 32.91934852])
We can now inspect the result of the optimization with gpflow.utilities.print_summary(m):
[7]:
gpflow.utilities.print_summary(m, fmt="notebook")
| name | class | transform | prior | trainable | shape | dtype | value |
|---|---|---|---|---|---|---|---|
| VGP.kernel.variance | Parameter | Softplus | True | () | float64 | 32.919348524016 | |
| VGP.kernel.lengthscales | Parameter | Softplus | True | () | float64 | 1.6358923591506107 | |
| VGP.num_data | Parameter | Identity | False | () | int32 | 50 | |
| VGP.q_mu | Parameter | Identity | True | (50, 1) | float64 | [[-1.11966222e+00... | |
| VGP.q_sqrt | Parameter | FillTriangular | True | (1, 50, 50) | float64 | [[[4.55452987e-01, 0.00000000e+00, 0.00000000e+00... |
In this table, the first two lines are associated with the kernel parameters, and the last two correspond to the variational parameters. NOTE: In practice, \(q_\Sigma\) is actually parameterized by its lower-triangular square root \(q_\Sigma = q_\text{sqrt} q_\text{sqrt}^T\) in order to ensure its positive-definiteness.
For more details on how to handle models in GPflow (getting and setting parameters, fixing some of them during optimization, using priors, and so on), see Manipulating GPflow models.
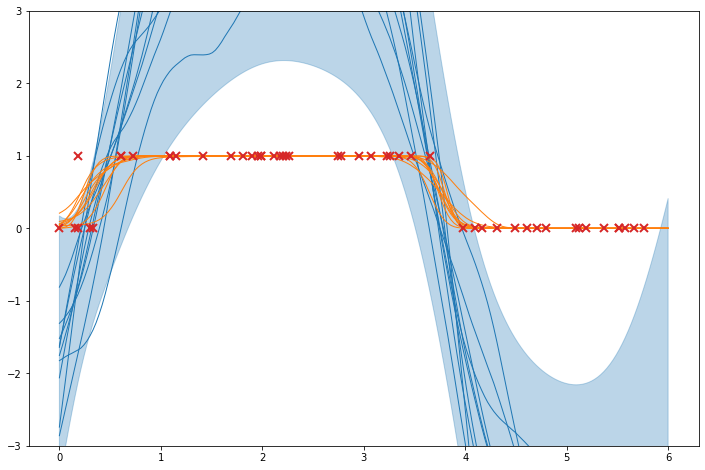
Predictions#
Finally, we will see how to use model predictions to plot the resulting model. We will replicate the figures of the generative model above, but using the approximate posterior distribution given by the model.
[8]:
plt.figure(figsize=(12, 8))
# bubble fill the predictions
mu, var = m.predict_f(x_grid)
plt.fill_between(
x_grid.flatten(),
np.ravel(mu + 2 * np.sqrt(var)),
np.ravel(mu - 2 * np.sqrt(var)),
alpha=0.3,
color="C0",
)
# plot samples
tf.random.set_seed(6)
samples = m.predict_f_samples(x_grid, 10).numpy().squeeze().T
plt.plot(x_grid, samples, "C0", lw=1)
# plot p-samples
p = invlink(samples)
plt.plot(x_grid, p, "C1", lw=1)
# plot data
plt.plot(X, Y, "C3x", ms=8, mew=2)
plt.ylim((-3, 3))
[8]:
(-3.0, 3.0)
Two-dimensional example#
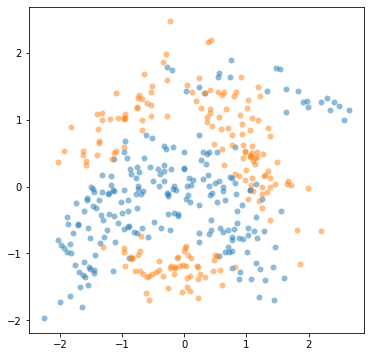
In this section we will use the following data:
[9]:
X = np.loadtxt("data/banana_X_train", delimiter=",")
Y = np.loadtxt("data/banana_Y_train", delimiter=",").reshape(-1, 1)
mask = Y[:, 0] == 1
plt.figure(figsize=(6, 6))
plt.plot(X[mask, 0], X[mask, 1], "oC0", mew=0, alpha=0.5)
_ = plt.plot(X[np.logical_not(mask), 0], X[np.logical_not(mask), 1], "oC1", mew=0, alpha=0.5)
The model definition is the same as above; the only important difference is that we now specify that the kernel operates over a two-dimensional input space:
[10]:
m = gpflow.models.VGP(
(X, Y), kernel=gpflow.kernels.SquaredExponential(), likelihood=gpflow.likelihoods.Bernoulli()
)
opt = gpflow.optimizers.Scipy()
opt.minimize(
m.training_loss, variables=m.trainable_variables, options=dict(maxiter=25), method="L-BFGS-B"
)
# in practice, the optimization needs around 250 iterations to converge
[10]:
fun: 109.15371512976827
hess_inv: <80602x80602 LbfgsInvHessProduct with dtype=float64>
jac: array([ 1.06489693e+00, 1.81366908e-01, 7.91943514e-01, ...,
-7.61766531e-06, 1.23786174e+00, -8.66976050e-01])
message: 'STOP: TOTAL NO. of ITERATIONS REACHED LIMIT'
nfev: 27
nit: 25
njev: 27
status: 1
success: False
x: array([ 3.71326474e-01, -2.76788131e-01, 1.14292753e+00, ...,
9.99990748e-01, 2.46208825e-03, 5.34079748e+00])
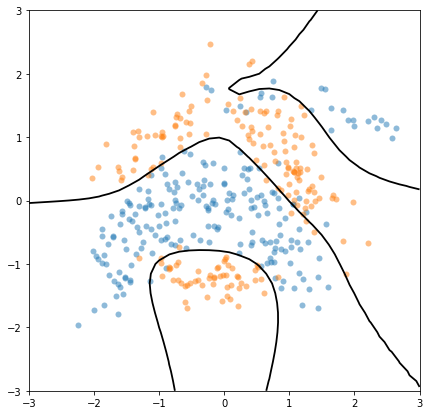
We can now plot the predicted decision boundary between the two classes. To do so, we can equivalently plot the contour lines \(E[f(x)|Y]=0\), or \(E[g(f(x))|Y]=0.5\). We will do the latter, because it allows us to introduce the predict_y function, which returns the mean and variance at test points:
[11]:
x_grid = np.linspace(-3, 3, 40)
xx, yy = np.meshgrid(x_grid, x_grid)
Xplot = np.vstack((xx.flatten(), yy.flatten())).T
p, _ = m.predict_y(Xplot) # here we only care about the mean
plt.figure(figsize=(7, 7))
plt.plot(X[mask, 0], X[mask, 1], "oC0", mew=0, alpha=0.5)
plt.plot(X[np.logical_not(mask), 0], X[np.logical_not(mask), 1], "oC1", mew=0, alpha=0.5)
_ = plt.contour(
xx,
yy,
p.numpy().reshape(*xx.shape),
[0.5], # plot the p=0.5 contour line only
colors="k",
linewidths=1.8,
zorder=100,
)
Further reading#
There are dedicated notebooks giving more details on how to manipulate models and kernels.
This notebook covers only very basic classification models. You might also be interested in: * Multiclass classification if you have more than two classes. * Sparse models. The models above have one inducing variable \(U_i\) per observation point \(X_i\), which does not scale to large datasets. Sparse Variational GP (SVGP) is an efficient alternative where the variables \(U_i\) are defined at some inducing input locations \(Z_i\) that can also be optimized. * Exact inference. We have seen that variational inference provides an approximation to the posterior. GPflow also supports exact inference using Markov Chain Monte Carlo (MCMC) methods, and the kernel parameters can also be assigned prior distributions in order to avoid point estimates.
References#
Hannes Nickisch and Carl Edward Rasmussen. ‘Approximations for binary Gaussian process classification’. Journal of Machine Learning Research 9(Oct):2035–2078, 2008.