GPflow manual¶
You can use this document to get familiar with GPflow. We’ve split up the material into four different categories: basics, understanding, advanced needs, and tailored models. We have also provided a flow diagram to guide you to the relevant parts of GPflow for your specific problem.
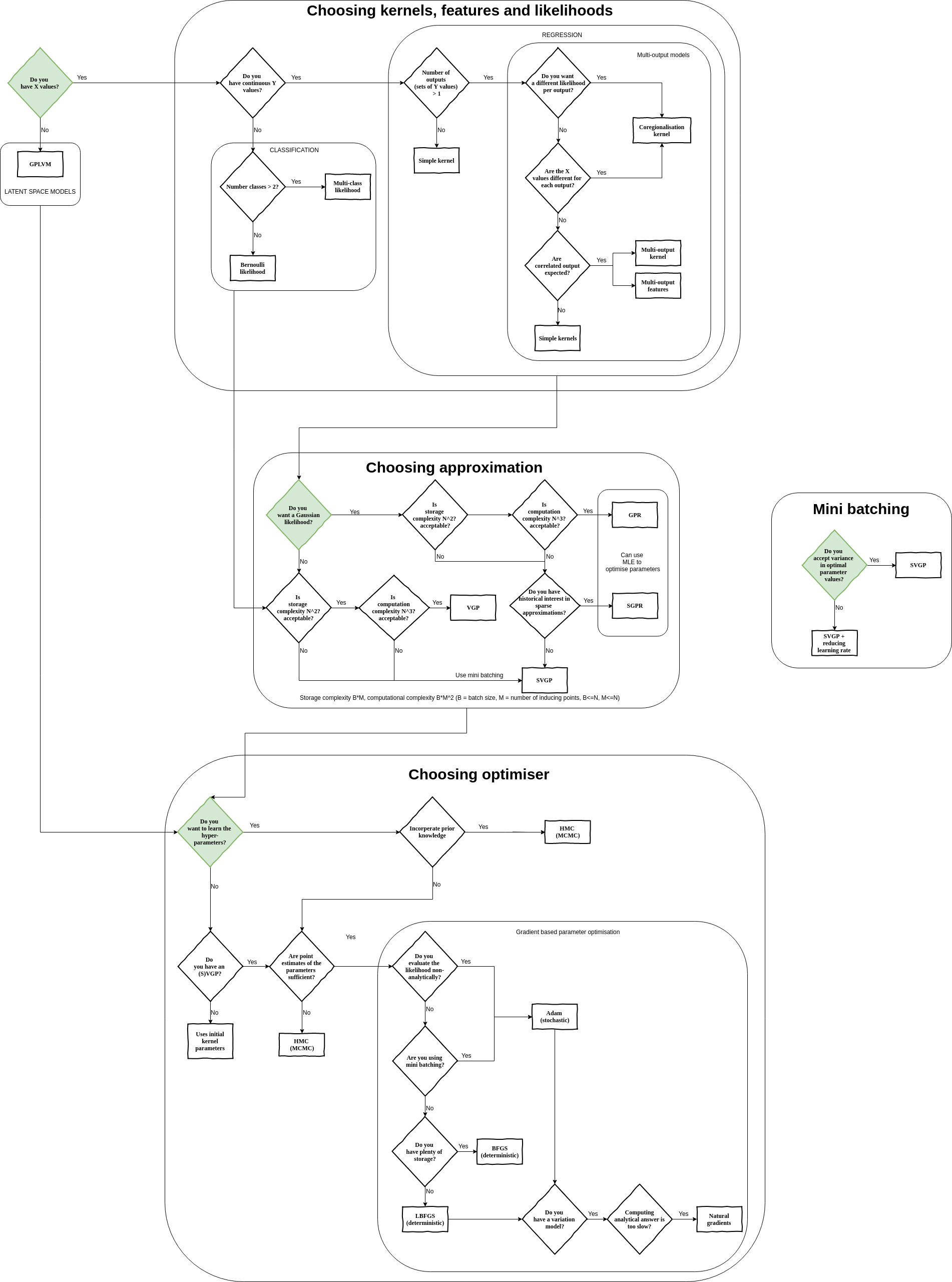{kind=link}
GPflow 2¶
Users of GPflow 1 should check the upgrade guide to GPflow 2.
Basics¶
This section covers the elementary uses of GPflow, and shows you how to use GPflow for your basic datasets with existing models.
In regression.ipynb and classification.ipynb we show how to use GPflow to fit simple regression and classification models (Rasmussen and Williams, 2006).
In gplvm.ipynb we cover the unsupervised case, and showcase GPflow’s Bayesian Gaussian Process Latent Variable Model (GPLVM) (Titsias and Lawrence, 2010).
In each notebook we go over the data format, model setup, model optimization, and prediction options.
Understanding¶
This section covers the building blocks of GPflow from an implementation perspective, and shows how the different modules interact as a whole.
GPflow with TensorFlow 2 for handling datasets, training, monitoring, and checkpointing.
Advanced needs¶
This section explains the more complex models and features that are available in GPflow.
Models¶
Markov Chain Monte Carlo (MCMC): using Hamiltonian Monte Carlo to sample the posterior GP and hyperparameters.
Ordinal regression: using GPflow to deal with ordinal variables.
Gaussian process regression with varying output noise for different data points, using a custom likelihood or the
SwitchedLikelihood, and Heteroskedastic regression with a multi-latent likelihood.Multiclass classification for non-binary examples.
GPs for big data: using GPflow’s Sparse Variational Gaussian Process (SVGP) model (Hensman et al., 2013; 2015). Use sparse methods when dealing with large datasets (more than around a thousand data points).
Multi-output models with coregionalisation: for when not all outputs are observed at every data point.
Multi-output models with SVGPs: more efficient when all outputs are observed at all data points.
Inter-domain Variational Fourier features: how to add new inter-domain inducing variables, at the example of representing sparse GPs in the spectral domain.
Manipulating kernels: information on the covariances that are included in the library, and how you can combine them to create new ones.
Convolutional GPs: how we can use GPs with convolutional kernels for image classification.
Fast predictions by caching: how to use caching to speed up repeated predictions.
Features¶
Natural gradients: how to optimize the variational approximate posterior’s parameters.
Monitoring optimisation: how to monitor the model during optimisation: running custom callbacks and writing images and model parameters to TensorBoards.
Tailored models¶
This section shows how to use GPflow’s utilities and codebase to build new probabilistic models. These can be seen as complete examples.
Kernel design: how to implement a covariance function that is not available by default in GPflow. For this example, we look at the Brownian motion covariance.
Mixing TensorFlow models with GPflow: two ways to combine TensorFlow neural networks with GPflow models.
External mean functions: how to use a neural network as a mean function.
Mixture density network: how GPflow’s utilities make it easy to build other, non-GP probabilistic models.
Theoretical notes¶
The following notebooks relate to the theory of Gaussian processes and approximations. These are not required reading for using GPflow, but are included for those interested in the theoretical underpinning and technical details.
Demonstration of the upper bound of the SGPR marginal likelihood
Comparing FITC approximation to VFE approximation: why we like the Variational Free Energy (VFE) objective rather than the Fully Independent Training Conditional (FITC) approximation for our sparse approximations.
A ‘Sanity check’ notebook that demonstrates the overlapping behaviour of many of the GPflow model classes in special cases (specifically, with a Gaussian likelihood and, for sparse approximations, inducing points fixed to the data points).
References¶
Carl E Rasmussen and Christopher KI Williams. Gaussian Processes for Machine Learning. MIT Press, 2006.
James Hensman, Nicolo Fusi, and Neil D Lawrence. ‘Gaussian Processes for Big Data’. Uncertainty in Artificial Intelligence, 2013.
James Hensman, Alexander G de G Matthews, and Zoubin Ghahramani. ‘Scalable variational Gaussian process classification’. Proceedings of the Eighteenth International Conference on Artificial Intelligence and Statistics, 2015.
Michalis Titsias and Neil D Lawrence. ‘Bayesian Gaussian process latent variable model’. Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, 2010.